Cómo construir una pirámide de población con Populate Data y D3

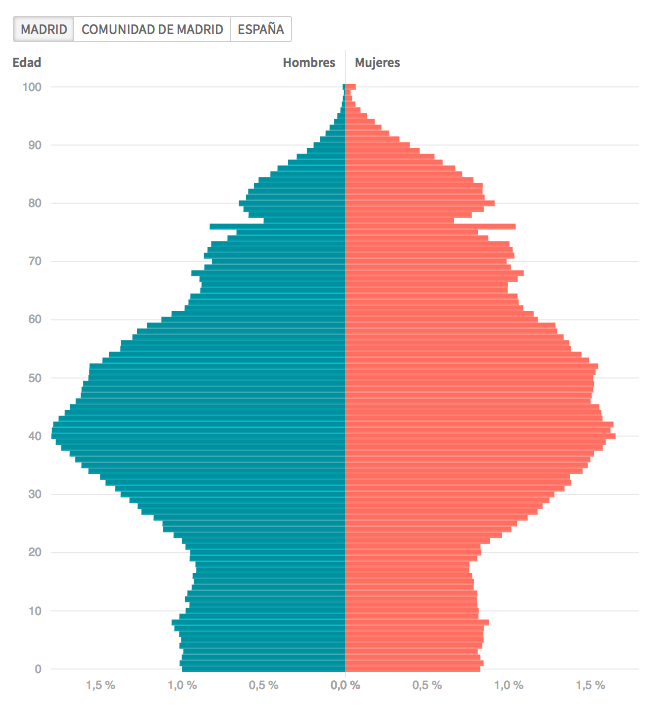
En este tutorial vamos a describir cómo utilizar Populate Data para obtener los datos necesarios para constuir una pirámide de población con HTML y D3.js como esta:
Populate Data es un servicio ofrecido por Populate que agrupa multitud de fuentes de datos públicos y privados y que permite consumirlos de forma unificada a través de una API.
Buscar datos en Populate Data
Para esta visualización en concreto necesitamos los datos del INE del padrón contínuo de población municipal por edad y sexo. Utilizaremos el explorador de datos para encontrar un dataset con esta información:
De entre todos los datasets agrupados en la categoría población hay uno llamado ds-poblacion-municipal-edad-sexo que contiene información a nivel municipal del número de habitantes de cada municipio agrupados por edad y sexo. Es un dataset que se actualiza anualmente y tiene las siguientes columnas:
value: el valor de la poblacióndate: el año del datosex: el sexoage: el añolocation_id: el identificador del municipio en base al código INEprovince_id: el identificador de la provincia en base al código INEautonomous_region_id: el identificador de la comunidad autónoma en base al código INEid: un identificador interno para acceder a un dato en concreto de forma rápida
La información sobre los códigos INE de los municipios se puede encontrar en el propio INE, o se puede utilizar alguna referencia externa, como la lista con la que trabajamos en Populate de la gema ine-places.
Los datos de una serie de Populate Data vienen en formato tabla e incluyen información de varios años y, en este caso, de varios municipios. Para nuestra visualización, denemos filtrar por un año en concreto y un municipio utilizando su código INE.
Según los diferentes puntos de acceso descritos en documentación de la API, la URL donde se obtienen los datos de este dataset es /populate-data-tutorials/datasets/ds-poblacion-municipal-edad-sexo y le vamos a añadir unos parámetros para filtrar:
filter_by_date=2018, para obtener sólo datos de 2018filter_by_location_id=28079, para obtener sólo los datos de un municipio en concreto (donde 28079 es el código INE de Madrid).except_columns=_id,province_id,location_id,autonomous_region_id, para mejorar el rendimiento de la página, también vamos a indicar en la petición de la API que se excluyan ciertas columnas que no vamos a utilizar
Además, podemos indicar en qué formato queremos los datos concatenando .csv o .json después del nombre del dataset. En nuestro caso optamos por CSV porque es más ligero que JSON, y porque en D3 es indiferente trabajar con un formato o el otro.
La URL final, por tanto quedará así:
https://data.populate.tools/populate-data-tutorials/datasets/ds-poblacion-municipal-edad-sexo.csv?
filter_by_date=2017
&filter_by_location_id=28079
&except_columns=_id,province_id,location_id,autonomous_region_id
La respuesta de la API a esta petición es un CSV con esta forma:
value,age,date,sex
16369,23,2018,M
20598,28,2018,M
19035,26,2018,M
20076,27,2018,M
14192,63,2018,V
13782,19,2018,M
13438,15,2018,M
12963,18,2018,M
13559,18,2018,V
21989,53,2018,V
21395,54,2018,V
...
Explorando los metadatos de un dataset
Populate Data ofrece un punto de acceso con metadatos de cada uno de los datasets en formato JSON. En los metadatos se guarda la siguiente información:
- “name”: nombre del dataset
- “frequency_type”: frecuencia de publicación de los datos
- “location_type”: unidad geográfica del dato
- “data_type”: tipo de datos de la columna “value”
- “id_format”: formato de la columna ID
- “properties”: un esquema JSON con los nombres de las columnas y sus tipos
- “dimensions”: un esquema JSON con las columnas que son dimensiones y sus valores. Por ejemplo en nuestro dataset, las columnas dimensión son “sex” y “age”.
- “indicator”: metainformación de la fuente de datos, y su URL
- “last_datum”: fecha del último dato del dataset
En un próximo tutorial describiremos en detalle cada uno de estos campos de metadatos.
Para acceder a esa información utilizamos la URL de un dataset y le añadimos el segmento /metadata.json, por ejemplo para el dataset de nuestra visualización: /populate-data-tutorials/datasets/ds-poblacion-municipal-edad-sexo/metadata.json
Volviendo a nuestra visualización, como vamos a necesitar agrupar los valores por edad y sexo, comprobaremos los valores de estas dos dimensiones en los metadatos. Para la columna “sexo”, sabemos que los valores son “M” y “V”. La columna edad muestra enteros de 0 a 99 y luego en 100 el valor se llama “100 y más”, pero lo convertiremos a entero por simplificar.
Obtener datos para la visualización
No queremos entrar en detalle de cómo construir la visualización en D3.js, pero vamos a describir cómo obtendríamos los datos desde D3.js (v5) y las transformaciones que necesitaríamos en este caso. Cuando trabajamos en una visualización solemos seguir esta estructura:
- Preparar el esqueleto de la visualización: el svg, las escalas y los dominios, escalas de color, ejes, etc
- Obtener los datos a través de la API, transformarlos según nos convenga y dejar una variable
datapreparada para ser usada y bindeada - Renderizar
- Añadir funciones para actualizar datos, interactividad y re-renderizado
Para esta visualización realizamos una única llamada a Populate Data, donde obtenemos la población para cada año y edad y convertiremos el valor en porcentaje, habiendo calculado previamente el total de hombres y mujeres para cada edad.
// Prepare variables
let currentYear = 2018
let populateDataToken = "FILLME";
let locationId = 28079;
let datasetName = "ds-poblacion-municipal-edad-sexo";
let populateDataURL = `https://data.populate.tools/populate-data-tutorials/datasets/${datasetName}.csv?filter_by_date=${currentYear}&filter_by_location_id=${locationId}&except_columns=_id,province_id,location_id,autonomous_region_id`;
let population = d3.csv(populateDataURL).header("authorization", "Bearer " + populateDataToken);
d3.queue()
.defer(population.get)
.await(function(error, jsonPopulation) {
if (error) throw error
// Convert to numbers
jsonPopulation.forEach(d => {
d.age = parseInt(d.age);
d.value = Number(d.value);
})
// Sort data by age column
jsonPopulation.sort((a,b) => a.age - b.age);
// Calculate the total amount of men and women
const totalMen = this._sumBy(jsonPopulation.filter(p => p.sex === "V"), "value")
const totalWomen = this._sumBy(jsonPopulation.filter(p => p.sex === "M"), "value")
// Prepare data variable with the value converted to a percentage
let data = jsonPopulation.map((item) => {
item.value_pct = (item.sex === "V") ? (item.value / totalMen) : (item.sex === "M") ? (item.value / totalWomen) : 0;
return item
});El resultado de este snippet de código es un objeto data con un atributo value con el valor para cada edad y sexo y un atributo value_pct con el porcentaje del valor para cada sexo. Ese objeto ya se puede bindear con D3 y utilizarse para construir la visualización.
Consulta la página de Populate Data para leer más o pedir más información.